Make sure you’ve read everything in the Intermission module before proceeding.
Foundation concepts you need for this module
Revise the foundation material on mathematics from “Variables and indexes” up to “Functions”, and the recommended reading “Vectors and their uses” before watching the videos.
Module content
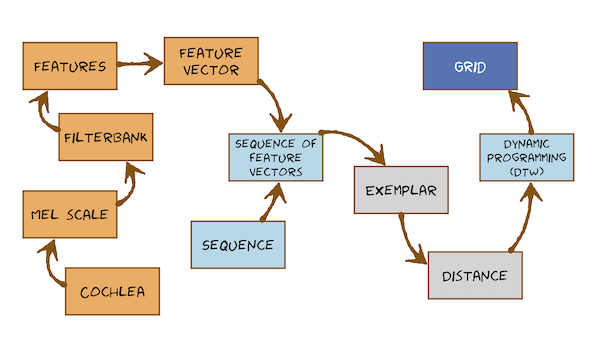
This is the start of the Automatic Speech Recognition material. In this module, we will make a preliminary attempt to extract salient features from speech signals, then use pattern matching to compare an unlabelled sample of speech to several stored samples with known labels (“exemplars”). Start with this very simple post, which defines the problem as one of extracting a feature vector (here with just 2 dimensions) and then doing pattern matching by measuring distance in feature space to exemplars: A super-simple speech recogniser
But that won’t handle anything other than stationary speech sounds. We need a way to deal with words and sequences of words. The problem is non-trivial because it involves sequences of variable length. This is recurring theme in Speech Processing, and in Natural Language Processing more generally.
Now work through the videos and readings which introduces a simple approach to pattern matching for variable length sequences: Dynamic Time Warping.
Here’s what you’re going to learn in this module:
Lecture Slides
Thursday lecture slides (google) [updated: 5 Nov 2024]