The current version of this course has a better layout and much better video content.

Introduction
An introduction to what this course covers, how it is taught, a brief history lesson, and a survey of current issues in speech synthesis.
Introduction to the course
Course outline. A taster of what is to come, by listening to a variety of TTS systems.
History
A brief history of text-to-speech synthesis, to provide some context for the state-of-the art systems that this course will cover.
Key challenges
Taylor identifies the key challenges in text-to-speech. Of these, the generation of natural human-sounding speech is going to be the…
Understanding the problem
If we believe Taylor when he says we generally only need shallow processing of the text, then we can state…
Looking ahead
A very quick look at some interesting applications of TTS, to motivate the techniques that we will cover later in…
Unit selection
Unit selection: how waveform generation is achieved through selection and concatenation of waveform segments, the data required to do this, and the limitations of this approach.
The method
It seems simple: choose a suitable sequence of pre-recorded speech segments, and play them back in the right order. But…
The database
The quality of a unit selection system depends very much on the speech database, both the quality of the recorded…
Evaluation
How do we evaluate a speech synthesiser? Almost always, we will need to play samples of synthetic speech to listeners and obtain some response from them.
Introduction
It's probably obvious that we need to evaluate any speech synthesiser, but let's pause and ask why that is.
Why evaluate?
What are we trying to get our of our evaluation? Do we need to know how to improve the system,…
What to evaluate?
Depending on our goals, we may need to evaluate the whole end-to-end TTS system, or just some of its components.
Which aspects?
It's important to be very specific about which aspects of the system we are evaluating: do we want to measure…
How to evaluate
In general, we are going to need some listeners, but what exactly shall we have them do?
Test design
Careful design will make sure listeners do the task we want them to, and that there are no unwanted effects.
Materials
The choice of appropriate text materials needs to be guided by what we are trying to measure, and what kind…
Signal processing for speech synthesis
Before moving on to parametric speech synthesis, we need to learn more about signal processing. In particular, how can we represent speech as a set of parameters that are suitable for statistical modelling?
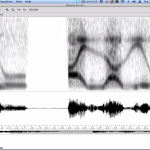
F0 estimation
A key parameter in any parametric representation of speech is the fundamental frequency, F0. Estimating it from speech is not…
Vocoding
In order to model speech, we need a parametric representation of it. This might be done using a source filter…
Statistical parametric speech synthesis
That's quite a mouthful, but we need to use a general term because this topic includes both Hidden Markov Models and Neural Networks for waveform generation.
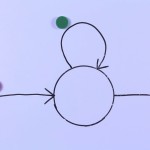
HMM-based synthesis
Hidden Markov Models are generative models, although their most common application is classification (Automatic Speech Recognition). But, of course we…
DNN-based synthesis
In HMM-based speech synthesis, the hard work is done by a regression tree. Trees are rather naive models, so why…
Hybrid speech synthesis
There are various ways to combine the strengths of machine learning (to deal with data sparsity) and waveform concatenation (for highly natural-sounding speech), and these so-called hybrid methods can do that very effectively.
Overview
A first look at how we can combine generation from a statistical model with concatenation of waveforms.




















 This is the new version. Still under construction.
This is the new version. Still under construction.