We’ll start by assuming that we have a large database of speech from a single speaker, and that it has been accurately labelled with phone boundaries and suprasegmental information such as phrase boundaries.

A toy example
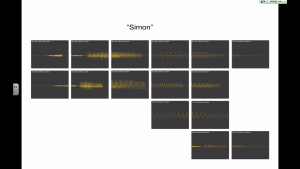
Before getting into the details, let's try a toy example to get a feel for why unit selection is so much better than diphone synthesis.
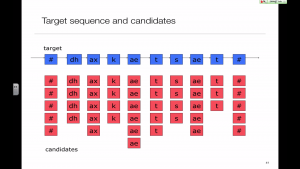
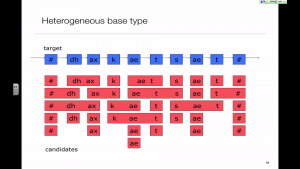
Unit selection is a search problem
The key difference with old-fashioned diphone synthesis is that the database now contains multiple examples of each diphone type. Therefore, the problem of synthesis becomes one of selecting from amongst many possible unit sequences.
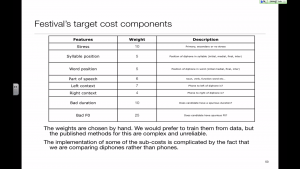
The cost functions
The search is formulated as a minimisation of a sum of cost functions. The cost functions measure the linguistic and acoustic suitability of each possible unit sequence.
Alternative unit types
One reason that unit selection sounds so much better than diphone synthesis is that there are fewer concatenation points. One way to have fewer concatenations would be to increase the size of the unit type, although we will see that a simple diphone or half-phone system can be made to effectively use larger units.
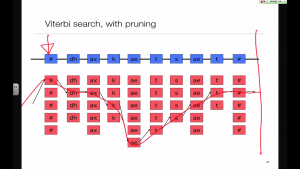
Streaming synthesis
Just as in Automatic Speech Recognition, a simple implementation of Viterbi search (i.e., dynamic programming) must wait until the end of the utterance before perfuming a traceback to recover the sequence. That isn't convenient for some applications, so we need a method for 'online' or 'streaming synthesis'.
Prosody
Prosody generation in unit selection can be done implicitly, via an IFF target cost, or explicitly using an ASF target cost.

 This is the new version. Still under construction.
This is the new version. Still under construction.