
Creating the script
The ideal database would have every unit in every possible linguistic context. That's impossible. We aim for the best coverage in a limited number of sentences.
The effect of coverage
In general a larger database covers more units-in-context and so should give better quality synthesis.
Sources of text
Text can be drawn from many possible sources, but we need to take care about the type of material and any copyright restrictions.
Annotating the database
The labels need to be consistent with predictions from the front-end, yet correspond to how the speaker said the utterance.
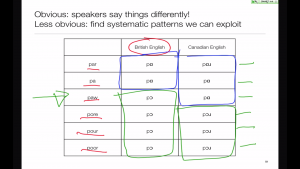
Dictionaries for accents
Self-consistency is important for unit selection - units with the same label need to be pronounced the same - but different accents make things more complicated.
Automatic vs manual labelling
Given unlimited resources, would we manually annotate the database instead of using forced alignment?
Labelling other properties
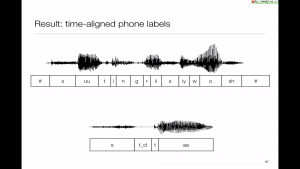
The database needs to be labelled with more than just time-aligned phones. Where are those labels going to come from?
More interesting speech material
The speaking style of the database determines that of the synthetic speech, so how about recording more interesting speech material?
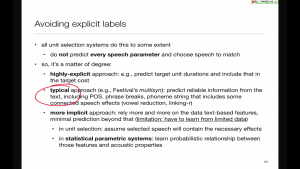
Implicit vs explicit labels
The target cost can use explicit information such as acoustic properties, or rely on implicit textual features. The database needs annotating accordingly.
The database
The quality of a unit selection system depends very much on the speech database, both the quality of the recorded speech and the accuracy of the labels.




 This is the new version. Still under construction.
This is the new version. Still under construction.