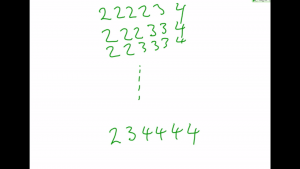Reading
Jurafsky & Martin – Section 9.7 – Embedded training
Embedded training means that the data are transcribed, but that we don't know the time alignment at the model or state levels.
The Baum-Welch algorithm is conceptually the hardest part of the entire course!

Introduction
The problem we need to solve is that we don't know the alignment between states and observations.
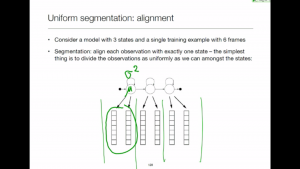
Uniform segmentation
A one-step method to get an initial estimate of model parameters. Typically used to initialise the models.
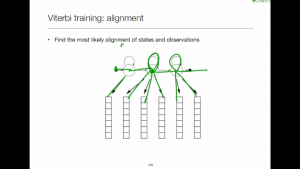
Viterbi training
Iteratively re-aligning the model with the data and updating the model parameters based on the single best alignment.
Baum-Welch (no maths)
By summing over all possible state sequences we marginalise away the state sequence: we don't care what value it takes.
Multiple training sequences
A trivial extension, as it turns out. The sum over all state sequences is just wrapped in a sum over all observation sequences (i.e., training examples).