This is the "prior" probability of W. It doesn't involve the observation sequence O, so can be computed without looking at the speech to be recognised.

Continuous speech (a first look)
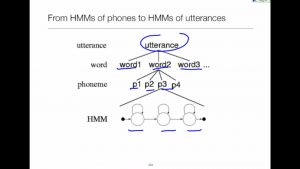
Once we understand token passing within a single HMM, the extension to continuous speech is surprisingly easy.
Reading
Jurafsky & Martin – Section 4.1 – Word Counting in Corpora
The frequency of occurrence of each N-gram in a training corpus is used to estimate its probability.
Jurafsky & Martin – Section 4.2 – Simple (Unsmoothed) N-Grams
We can just use raw counts to estimate probabilities directly.
Jurafsky & Martin – Section 4.3 – Training and Test Sets
As we should already know: in machine learning it is essential to evaluate a model on data that it was not learned from.
Jurafsky & Martin – Section 4.4 – Perplexity
It is possible to evaluate how good an N-gram model is without integrating it into an automatic speech recognition. We simply measure how well it predicts some unseen test data.
