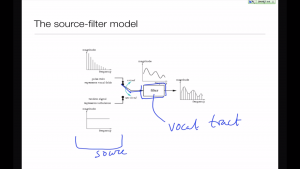
Finally we have a complete model of speech production that we can use from now on.
You are here:Home Courses Archived courses Speech Processing (up to 2016-17) The basics Source-filter model Putting source and filter together
speech.zone


Search the forums
Copyright © 2024 · Balance Child Theme on Genesis Framework · WordPress · Log in