
Using Praat, we synthesise a simple vowel-like sound, starting with a pulse train, which we pass through a filter with resonant peaks.
Continue reading...Using Praat, we synthesise a simple vowel-like sound, starting with a pulse train, which we pass through a filter with resonant peaks.
Continue reading...
The equation for entropy is very often presented in textbooks without much explanation, other than to say it has the desired properties. Here, I attempt an informal derivation of the equation starting from uniform probability distributions. A good way to think about information is in terms of sending messages. In the video, we send messages […]
Continue reading...
At the Parque de las Ciencias in Granada, Spain there is this long tube, open at the end nearest you and closed at the far end. We can calculate the length of this tube just from the audio recording, because we know the speed of sound. Here’s the waveform of part of the recording, showing […]
Continue reading...
A quick introduction to a very simple but widely-applicable model that can perform classification (predicting a discrete label) or regression (predicting a continuous value). The tree is learned from labelled data, using supervised learning. Before watching this video, you might want to check that you understand what Entropy is.
Continue reading...
Token passing is a really nice way to understand (and even to implement) Viterbi search for Hidden Markov Models. Here we see token passing in action, and you can look at the spreadsheet to see the calculations. To keep things simple, we are ignoring transition probabilities in this example. It would be simple to add them […]
Continue reading...
The spectrum and the spectrogram are much more useful ways of analysing speech signals than the waveform. We look at how to create them using Wavesurfer and what effect the analysis window size has on what we see.
Continue reading...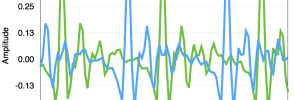
Most methods for estimating F0 start from autocorrelation. The idea is pretty simple: we are just looking for a repeating pattern in the waveform, which corresponds to the periodic vocal fold activity. For some waveforms, it might be possible to do that directly in the time domain, but in general that doesn’t work very well. […]
Continue reading... This is the new version. Still under construction.
This is the new version. Still under construction.