Forum Replies Created
-
AuthorPosts
-
Hi Rebecka,
Sorry about the delay in responding!
Your description of the relationship between the number of inputs and the DFT analysis frequencies is good. Sorry, I misunderstood your question in class and went on a bit of a tangent!
For your scenario: I would first just clarify that
“The number of input sample points in the analysis window equals the number of frequency outputs of applying the DFT to that window” which I think is what you are saying in any case.In point 2:
We are processing slices of the total wave, one window frame at a time. If we imagine that the square I have drawn over the dotted line is our window which we slide across the signal, then its width also determines what frequencies you can detect.
Yes!
Its width will determine what range of frequencies you could see BUT if you have set the sampling rate independently of the frame width then you will sometimes end up with a mismatch between which frequencies could be detected given window width vs. which frequencies are detected given the sample rate of the digitized signal. This results in the leakage effect in the frequency domain where we see a mismatch between where the formants appear in the plot vs. where they are supposed to appear given the harmonic structure that can be detected by our window.
I think you’ve got it, but it’s worth unpacking this a bit here!
1. If you have have a fixed number of samples per window, changing the sampling rate will change the length of the window (in seconds). Conversely, If you have a fixed sampling rate, changing the length of the input window (in seconds) will change the number of samples you can take in that window. So, if you always keep to the same number of samples in a window but change the sampling rate, DFT outputs will map to basis sinusoids of different frequencies.
2. Depending on what frequencies are actually in your input sample, you may get leakage with one sampling rate (due to change in window length) as opposed to the another. For example, assume your window is 10 samples long and your sampling rate is 1000 Hz. Then the DFT should be able to pick up multiples of 100 Hz faithfully. In contrast, if your sampling rate is 800 Hz (still 10 samples), the DFT would pick up multiples of 80 Hz. This means that a 100 Hz sine wave would appear as a single spike on the former, but cause leakage in the latter (spilling over into 80 Hz and 160 Hz, and potentially other frequencies in the spectrum).
– Is this correct or is it the case that the window width and the sampling rate are always set in tandem? Seeing as dt x N(samples) = window width, we have a close relationship between the two parameters which means that whatever sample rate we choose determines the width of our window. We don’t set them independently?
Yes, you’re right. We can consider window width in time and sampling rate independently, but this would then change the number of samples we can analyse in a window. In reality, the sampling rate is usually set first and then the window width is usually determined based on the application we have in mind (e.g. do we want a narrowband or wideband view of the spectrum? It turns out the seeing all the fine detail of the harmonic structure is not that use for word recognition, for example).
If this is the case then maybe my confusion above stems from the fact that I think of the process in several steps: first you digitize the analogue signal by sampling and then you “slide” a window across this signal to process it. Maybe this is totally wrong as the input to our system is instantaneous so you cannot separate the steps – segmenting and sampling take place simultaneously, as the analogue signal arrives in the system in real-time. ???
The input isn’t really instantaneous. The waveform needs to be sampled and quantized (i.e. discretized) so we can even get it onto the computer. We then do windowing and apply the DFT (and potentially other things) in the digital realm. So the leakage is really due to the fact that we can’t always know what exact frequencies will be in our (analogue) input (this is very much the case of speech as everyone’s voice is a bit different and so characterised by different frequency components!). Separately, we have constraints on memory for storing digital recordings (a higher sampling rate means you have to store more samples) and also for making sure we have a high enough sampling rate to capture the frequencies that are important for the task. For example, humans can hear up to around 22kHz but still understand people through telephones which only have 8kHz sampling rate (though we notice the loss of quality). Separate again are constraints based on what sort of frequency analysis we want to do (how much detail we actually want to extract).
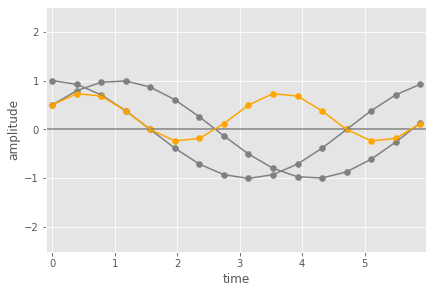
Is it the case that you are able to find the coefficients of the basis functions through multiplication because of symmetry reasons? If you look at my drawing I have tried to visualize what I imagine is happening. The two plots on the bottom are supposed to show the same wave, ie “what would happen if we multiplied two identical waves together?”. We would do 1×1 at the first sampling point and -1x-1 at the second sampling point. The sum would be 2. Conversely, the diagram at the top shows what happens if we multiply two dissimilar waves together. At the first sampling point we get 1×0.75 and at the second point we get -1×0.75 and therefore end up with the sum of 0. In other words, we get cancelling effects for dissimilar waves because the amplitude of one will be positive whereas the amplitude of the other will be negative at certain points in time and we therefore get some negative products when we perform this step-wise multiplication. These cancelling effects are the same phenomenon that makes the basis functions orthogonal because if you would perform this multiplication on any pair of basis functions – instead of a basis function and the composite wave – they would cancel each other out completely?Does my description make sense? Have I understood what you meant in the video?
There are a few different things going on here:
- You can find the DFT coefficients (i.e. the DFT outputs) by performing the dot product.
- You can see that the dot product between DFT basis sinusoids will be zero because of symmetry of sinusoids around the x-axis of a time versus amplitude plot.
First let’s consider
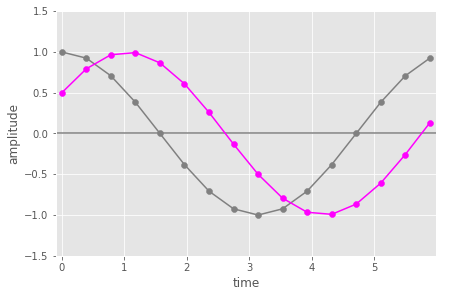
– an input 16 samples of 1 period of a cosine wave with a small phase shift (magenta)
– 16 samples of a cosine wave of the same frequency (hence period) but without the phase shift (this is equivalent to the 1st DFT basis sinusoid) (grey).
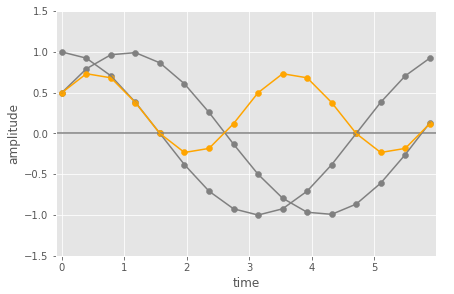
This next figure we see those two cosine wave, and the pairwise multiplication of the samples of those two waves (in orange).
Here you can see that the orange values are mostly above zero amplitude and the positive values have larger absolute values than the negative ones. When you add them up (as the last part of the dot product) you would get a non zero value (positive in this case). You can think of this as the average value of the multiplication points being above zero.
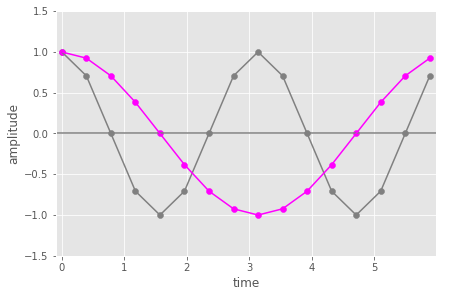
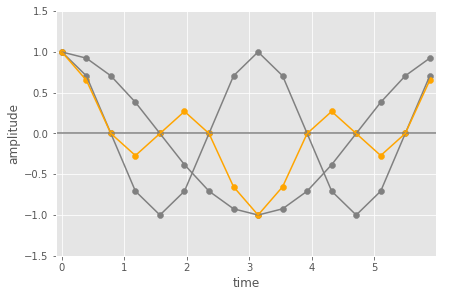
Now let’s look at the case where we the input is the 1st DFT basis sinusoid and we take the dot product with the 2nd DFT basis sinusoid (so twice the frequency of the 1st DFT basis sinusoids – 2 cycles in the same time window).
In this case, the pairwise multiplication results in values that are symmetric around zero amplitude. Over the period the average of the orange points will be zero (because the positive points are in in effect cancelled out by the negative ones).
You now might also think about this in terms of overall area under the curve being zero! But remember we don’t actually have a curve here, just the sampled points!
However, this links to the point (b) about integrals. Yes, it’s basically the same thing but since we are working in a discrete space we need to take sums instead of integrals. When dealing with continuous functions we use the Continuous Fourier Transform which takes the integral instead of the sum. The difference is that we have a limit of what dx can be (determined by the sampling rate) so we can’t make dx infinitely small as is required for an integral (but it’s the same concept). Instead we multiply the discrete samples that are aligned in time and sum them up.
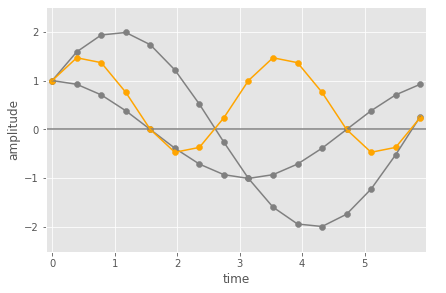
For point (c), Note that the dot product isn’t scaled, so it can be bigger than 1. The magnitude shown on the spectrum for a detected frequency will be proportional to the amplitude of that frequency in the input. You can see this in the figures below.
The first shows the same as above (same frequency with a phase shift) versus a version where the input has double the peak amplitude. The positive values in the pairwise multiplication (orange) are bigger, so the overall dot product (sum) value will be too.
Some these details are definitely easier to see if you go through the actual mechanics of the DFT equation. We’ve set the mathematical details as beyond the examinable scope of this course, but you can find some more detail on this in the Module 3 lab notebooks, specifically notebook 3 (“discrete Fourier Transform in detail”). This is marked as extension material but it still might be useful to play with the visualisation of the dot product at the end of the notebook.
Any complex periodic wave can be represented as a sum of weighted basis functions. The basis functions are orthogonal, meaning they have the same amplitude but are multiples of the lowest frequency sinusoid of the set. The question is how to find the coefficients / weights for these basis functions. The video explained that you take the sinusoid you want to weight and multiply it with the original wave. The product of this operation will be large for sinusoids which are similar to the original wave whereas it will be small for dissimilar sinusoids. This makes intuitive sense as you’d want to add more of the very similar basis functions than you’d want to add of the dissimilar ones when you add up sinusoids to create your complex wave.
We need to first clarify what “orthogonal” means here. The fact that the basis functions are orthogonal means that if you measure the similarity between the functions using a dot (aka inner) product (as we do in the DFT), the similarity will be zero. The fact that the sinusoids are multiples of the the lower frequency one guarantees this orthogonality property when we are dealing with discrete (i.e., sampled sinusoids) rather than continuous ones. This is what allows us to pick out the presence of specific frequencies with the DFT. When we do the dot product between the input and a specific basis sinusoid, we’re basically zeroing out all the frequencies and so just seeing how much of that basis sinusoid frequency is in the original signal.
To think about why the dot product works as a measure of similarity, we need to think about the sampled sinusoids as vectors. Each of the basis sinusoids consists of N samples (corresponding to the number of samples in the input window). This means we can think of each of the sinusoids as an N dimensional vector.
For example, let’s call the first basis sinusoid s1. The DFT represents this with N samples so s1 = [u1, u2,….,uN], where u1,..,uN represent the sampled amplitudes of that sinusoid in time. Similarly we can take second basis sinusoid as s2=[v1,v2,….,vN]. As sine waves they look like this:To calculate the dot product between s1 and s2 we first take the pairwise multiplication at each dimension of the vector, then sum all of those values together:
u1*v1+u2*v2+…+uN*Vn. So this gives us one number with corresponds to a how much the two vectors were pointing in the same direction. If this value is zero we intepret this geometrically as the vectors being orthogonal (i.e. perpendicular). Intuitively, you can think of this as meaning there is no correlation between the two vectors. This is a nice video that explains dot products and their geometric interpretation.
For the DFT the dot product is taken between the sampled input: x = [x1,…,xN] and each of the basis vectors s_k = [a1,….,aN].
So DFT[k] = x1*a1 + ….+ xN*aN.
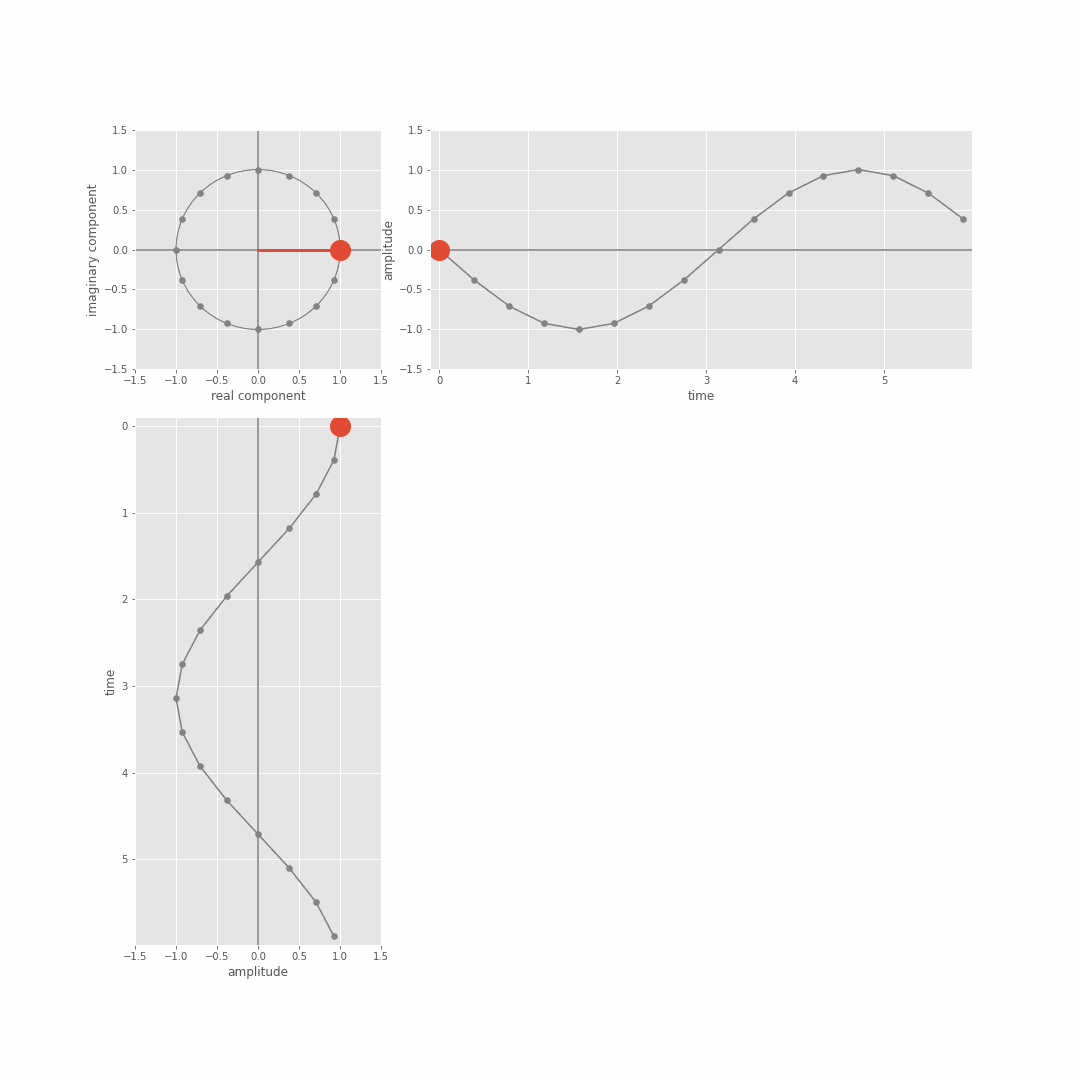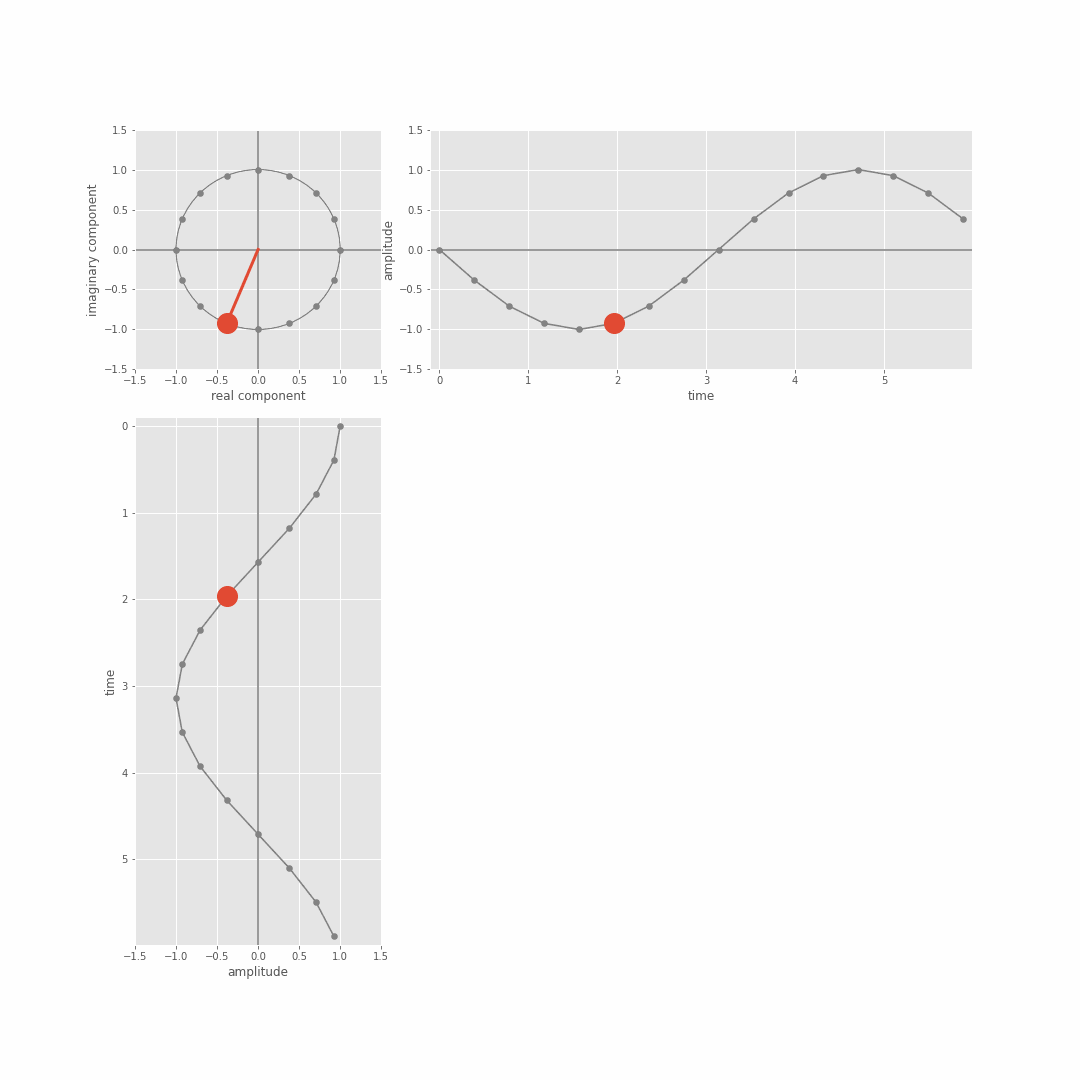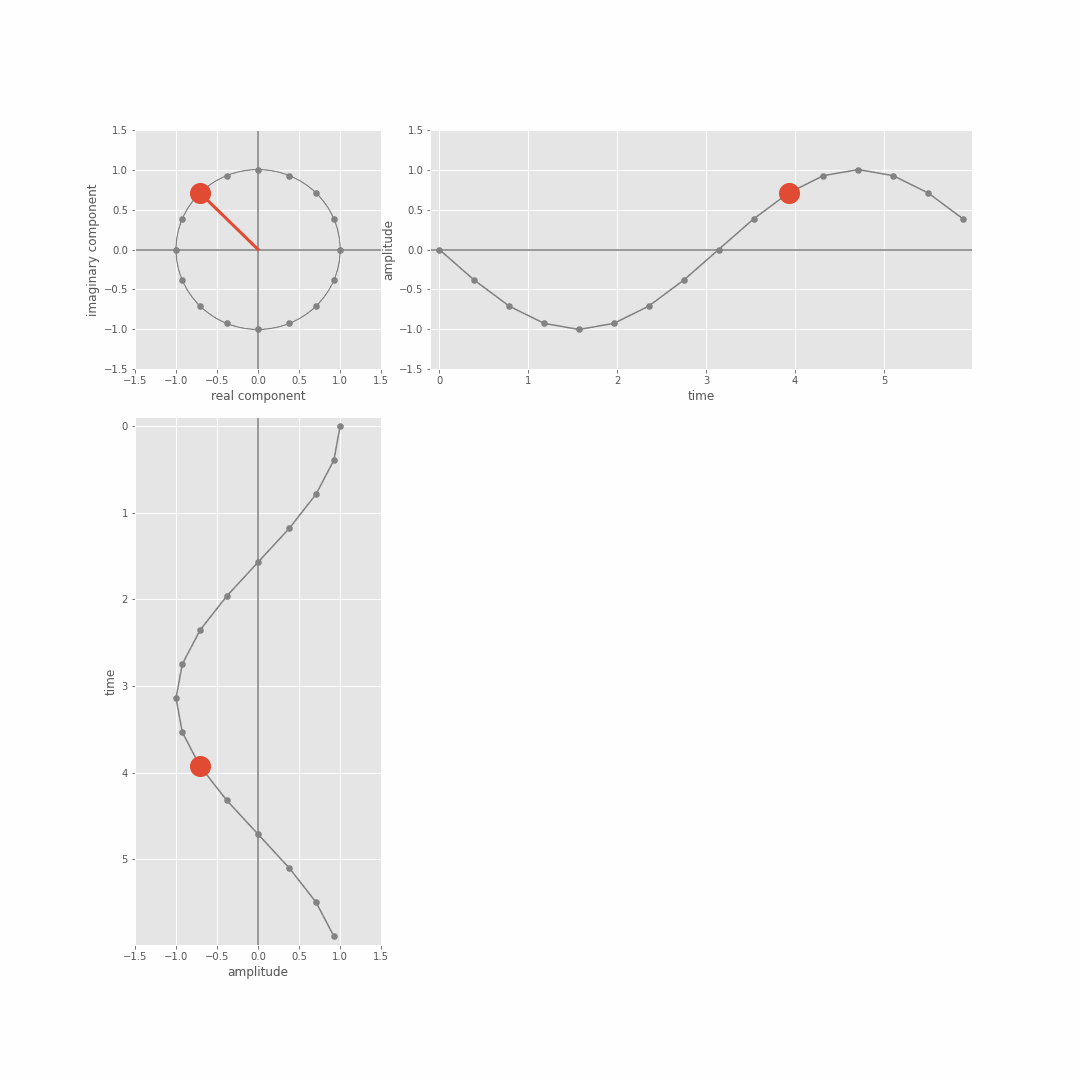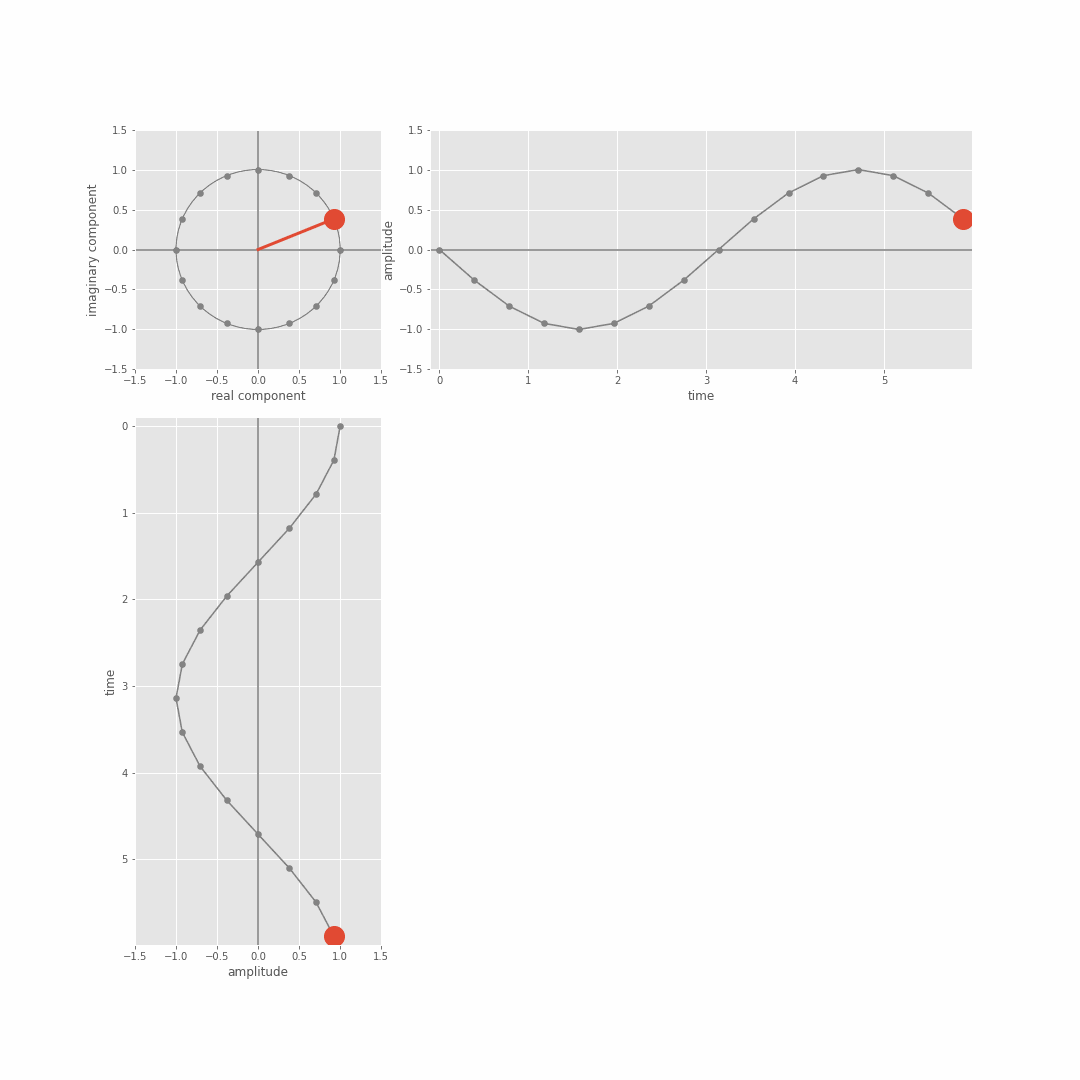
From this we can derive the magnitude (scale) and phase (shift) coefficients associated with different basis sinusoid frequencies. We just focused on magnitude in the lecture, but you can get the phase out of the result of the dot product too because the actual DFT dot product involves complex sinusoids (in the sense of complex numbers, a+jb with j=sqrt(-1)) not just real valued sine waves. There’s more detail on this Module 3 lab notebooks (more in the extension notebooks), but the general idea is that the DFT is actually taking the dot product between the (real valued) [x1,…,xN] and a complex sinusoid which we can in turn think of in terms of separate cosine and sine waves of a specific frequency. The following git shows the complex sinusuoid (cycles of the circle top left), and the relation to sine (top right) and cosine functions (bottom left).
[to be continued!…]
Hi Muminah,
Yes, there will be solutions/commentary for the phon and signals labs. I’ll try to post the phon ones next week and the signal ones soon after.
For the TTS and ASR parts of the course (week 5 onwards) you will be working on the course assignments though so there won’t be solutions posted, but you will get feedback on your submissions through the marking.
cheers,
CatherineHi Nickon,
You should watch the videos on speech.zone (i.e., the ones in the “videos” tab for the module) before the lecture.
The lectures will be live, so you should come in-person, but if you want to review it later you can watch the lecture recording via Learn.
cheers,
CatherineYou need to expand the sed command to match the entire line, eg.
^$USER .*$($here means the end of the line,^mean the beginning of the line). But there’s also a tricky thing with sed and newlines, so since you want to delete the whole line, you can use thedflag, i.e. delete:sed -i '/^$USER .*$/d' info.txt
This assumes that it’s just spaces separating the columns.
There are some more examples and explanation of the flags (probably too much info) here:
https://www.gnu.org/software/sed/manual/sed.htmlcheers,
CatherineYou may need to run this first for 32 bit compatibility with Ubuntu WSL:
sudo dpkg --add-architecture i386 sudo apt update
But I haven’t been able to check directly.
November 17, 2021 at 09:26 in reply to: Issue following Git instructions to install HTK on macbook #15281You might be able to fix this by adding this to the
configurecommand:CFLAGS="-I/opt/X11/include" ./configure --x-includes=/opt/X11/include/
This tells the compiler to look in
/opt/X11/includefor the missing files (which is what the flag is supposed to do)For other people: We ran into another error after this – I’ll look into it
cheers,
CatherineHi Dayyan and everyone,
I’ve emailed this to the class but just to post it here too:
The assessment will be:
- A 2 hour “take home” timed test to be done during the specified period (held on GradeScope)
- 50% of the final grade
- date: open from 12:00 Thursday 16th December 2021 to 23:59 Friday 17th December 2021.
This range is to accommodate exams and other commitments people had during that week. Hopefully everyone can find a convenient 3 hour slot in that day and a half in December!
cheers,
CatherineHi Lijia,
There are links to scanned copies if you click on links to the readings.
Jurafsky & Martin (2nd ed) – Section 8.1 – Text Normalisation
The library has provided these due to the ‘out of credit’ issue. If they are too hard to read due to the scanning, send me an email and we’ll sort something else out.
cheers,
CatherineHi Rory,
The constriction changes what frequencies are resonant (to be higher in the case you mentioned). This means that oscillations of the air particles at that frequency get a boost in energy, which we observe as amplification. As you would see in the spectrogram, a range of frequencies around the resonance are also amplified (The black formant band actually indicates a range of frequencies are boosted).
Oscillations at frequencies that are not so close the the resonant frequency will lose energy, so their amplitudes will go to zero (unless they are boosted by something else!).
In general how sharply frequencies around the natural resonant frequency drop off depends on the “tuning” of the system (a tuning fork is much more sharply tuned than the human vocal tract!).cheers,
CatherineHi Ian,
You’re right in saying that when we take a window, we ignore everything else that is happening outside the window. So if there are frequencies present in the signal that have a period longer than the window length, we won’t be able to capture them.
This isn’t quite shown in the example you give (though it may be just a typo!). If the window length=0.2 s, then 1/window length = 5 , so the minimum frequency you could capture with that window length is 5 Hz and multiples of that up to half the sampling rate. So in this case you would be able to capture a 10 Hz signal.
If instead the window length = 0.02 s, the frequencies would be 1/0.02 = 50 Hz, and multiples of that (100 Hz, 150 Hz, etc). So in that case, you wouldn’t accurately capture the 10 Hz wave. In this case, since the input frequency 10 Hz falls between the DFT analysis frequencies, you would get leakage: you would see the largest non-zero magnitude at 50 Hz, but also other frequencies in the DFT output will have non-zero magnitudes.
For your last question, the basis functions are exactly the sinusoids (cosine functions to be specific) with frequencies matching the DFT output frequencies. So, if you have an input size of N=10 samples, you will have N=10 basis functions. All (infinitely many) other potential sinsusoids are ignored as they are outside the basis set. So, you can kind of think of them as having zero coefficients, but it’s better to think of the ones that don’t match the DFT analysis frequencies as not being a part of that specific basis function set (determined by the input size and the sampling rate). In that case you only have to deal with N functions rather than an infinite number!
cheers,
CatherineThis question gets at one of the most important parts of understanding the DFT: The number of input samples determines which frequencies you can accurately detect with the DFT.
For a recording, we can assume that we have a fixed sampling rate, f_s, so the time between each sample, the sampling period, is 1/f_s. For example, if the sampling rate is f_s=1000Hz, the sampling period will be 1/1000 = 0.001 seconds.
So, 10 samples will capture a window size of 10*0.001=0.01 seconds.
Taking these 10 samples as input, we can all our input size N=10.The range of frequencies we can analyse with the DFT is determined by the sampling rate, but the number of frequencies we can actually analyse is determined by the size of the input. The frequencies we can analyse are exactly N points spread evenly from 0 to the sampling rate.
The lowest analysis frequency (associated with DFT[1]) will be the sampling rate/input size, f_s/N, and the other analysis frequencies will be multiples of that up to the sampling rate. So in the example above, the lowest analysis frequency will be f_s/N = 1000/10 = 100. So the DFT output will represent the 10 frequencies 100 Hz, 200 Hz, 300 Hz,…,1000 Hz.
This is essentially what the textbook is getting at: the ‘first harmonic’ mentioned in the text is the lowest analysis frequency. If we work from the DFT equations, we can (eventually) see that the lowest analysis frequency is the same as the frequency of a sine wave that has the same period as the window size. So if the window size is 0.01 seconds, the lowest analysis frequency will be 1/period = 1/0.01 = 100 Hz.
Now, for sampling rate 1000 Hz and input size N=10, we won’t be able to accurately tell if the input has a frequency component of 30 Hz, because this falls between the analysis frequencies (which are all multiples of 100 Hz).
If instead we analyze a longer window, e.g. 0.1 seconds, we would need N=100 samples (100*0.001=0.1 seconds). In this case the lowest analysis frequency will be f_s/N = 1000/100 = 10 Hz (equivalently, period=window size=0.1, frequency=1/period = 10 Hz). So the DFT output will represent N=100 frequencies: 10, 20, 30,…,1000 Hz. This time, with input size N=100 we will be able to capture an input frequency of 30 Hz, because it matches one of our DFT analysis frequencies in this case.
In general, given a fixed sampling rate, the longer the time window we want to analyze, the bigger the input size N will be, and the more frequencies we will be able to accurately detect in the input. This means higher frequency resolution. But if we take a longer window as input, we have less time resolution. For example, if we were to take the DFT over a whole diphthong like [ai], we won’t be able to “see” the changes in formants from the beginning of the vowel to the end as you just get one spectrum out for the whole window. To increase the time resolution, we need shorter windows but this means there are less frequencies we can detect with the DFT as the input size is decreased.
The length of window you want to use depends on what type of analysis you want to do. If we want to look at how the overall spectral envelope changes with detailed time resolution (e.g. to track changes in formants), and don’t care too much about the fine spectral details (like the harmonics due to the voice source) a shorter window would be preferred. If we wanted to capture more of the fine detail of harmonic structure and know that the sound is stable (like a sustained vowel) then we would prefer a longer window. In practice, since phones are very different in their spectral and temporal characteristics, we usually keep to a default window size and step (e.g. frame size=25 ms, frame step=10ms) and then do some other analysis to obtain the features we want. We’ll come back to this later in the course when we talk about feature inputs for ASR!
Here’s a link to the recording of discussion of this in the in the Q&A session (12/10/2021): Link to recording (Teams)
The videos are working for me. Could you tell me if there are specific videos that aren’t working for you?
Did you find a solution for this? If not could you ask Jacob Webber (who wrote Qualtreats) directly: j.j.webber@ed.ac.uk? I’m not sure what the expected syntax is for this code.
-
AuthorPosts
 This is the new version. Still under construction.
This is the new version. Still under construction.