- This topic has 1 reply, 2 voices, and was last updated 9 years, 7 months ago by
 .
.
Viewing 1 reply thread
{kind=link}
Viewing 1 reply thread
- You must be logged in to reply to this topic.
› Forums › Speech Synthesis › The front end › Duration prediction
Is duration prediction done at the segmental or suprasegmental level? is it computed using CART as classifier (using labels like) or using regression (giving duration in ms?)?
In Festival, and many other systems, duration is predicted at the segmental (i.e., phone) level. Festival uses a regression tree, because duration is a continuous value.
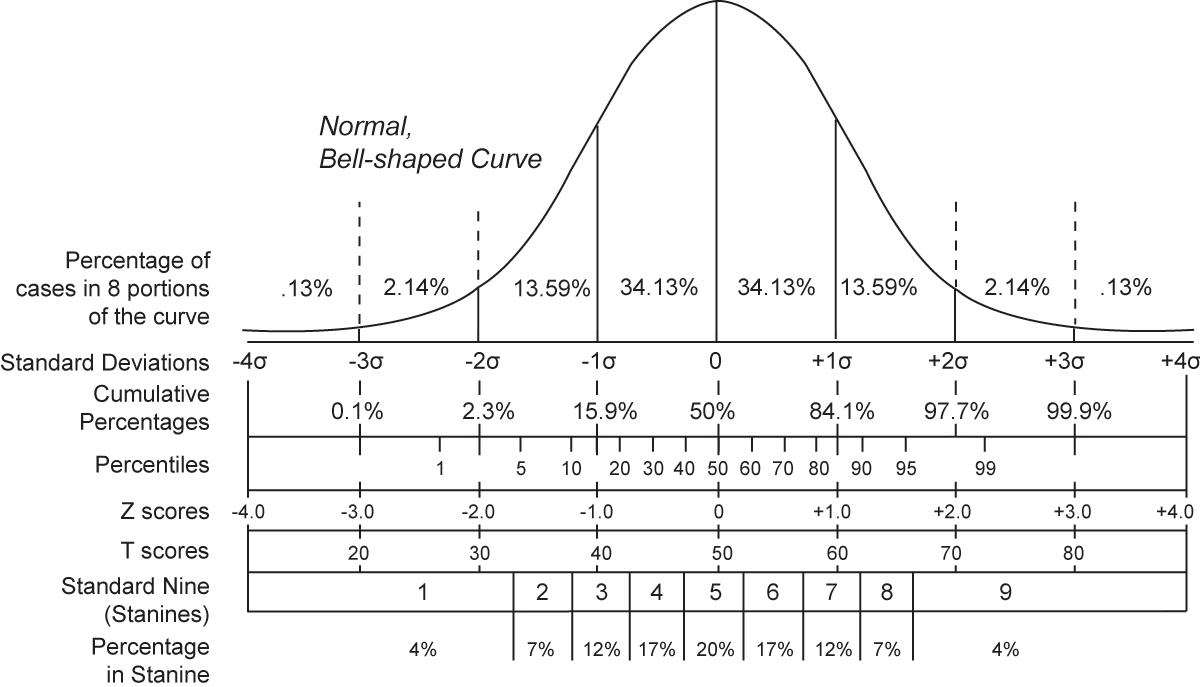
The tree could directly predict duration in ms or s. But it’s often better to predict what is called a z-score (the figure in that article is helpful). This is the duration expressed as the difference (in numbers of standard deviations) from the mean duration for that phoneme. Here’s what z-score means for duration:
large positive numbers: duration is a lot longer than average
small positive numbers: duration is bit longer than average
zero: duration is exactly equal to the average
negative numbers: duration is bit shorter than average
large negative numbers: duration is lot shorter than average
and we would expect z-scores in a relatively narrow range about the mean (+/- 2 would cover 96% of all cases).
Some forums are only available if you are logged in. Searching will only return results from those forums if you log in.
 This is the new version. Still under construction.
This is the new version. Still under construction.Copyright © 2025 · Balance Child Theme on Genesis Framework · WordPress · Log in