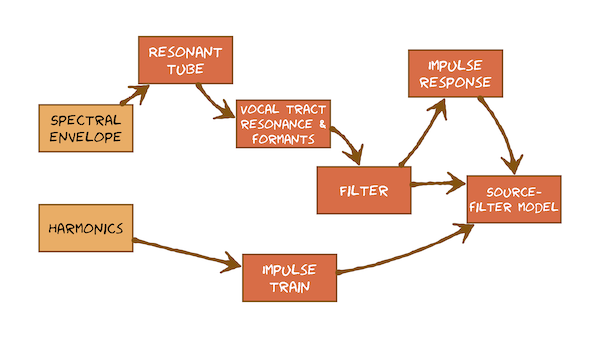
This module develops the source-filter model of speech, which was introduced from a phonetics perspective earlier and is something we’ll be coming back to again and again throughout the course. At first, it’s going to help you understand what you are seeing in speech signals when viewed in either the time domain or frequency domain. Later, it will form the basis of methods for manipulating speech during Speech Synthesis, and for extracting salient features for Automatic Speech Recognition. Here’s what you’re going to learn in this sequence of videos:
Lecture Slides
Slides for Thursday lecture (google slides) [updated 8/10/2024]