Hidden Markov Models are generative models, although their most common application is classification (Automatic Speech Recognition). But, of course we can generate new samples from them. That's how we use them for speech synthesis.

Introduction
Two ways to view HMM synthesis and an overview of how it fits in the text-to-speech pipeline.
Putting it all together
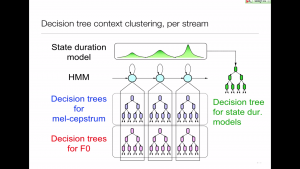
Separate regression trees for duration and each stream of acoustic parameters.
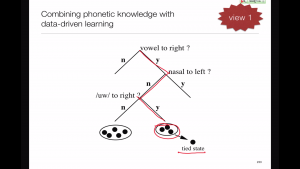
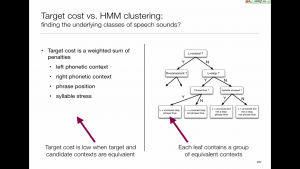
The connection to unit selection
These two seemingly very different approaches actually have a lot in common.




 This is the new version. Still under construction.
This is the new version. Still under construction.