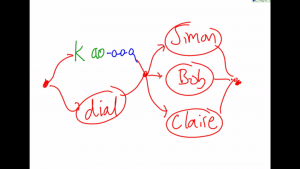
The idea of compiling al the models together is very natural, if we are taking the generative view.
Computing P(W)

What kind of language models are possible for continuous speech?
The idea of compiling al the models together is very natural, if we are taking the generative view.
What kind of language models are possible for continuous speech?
 This is the new version. Still under construction.
This is the new version. Still under construction.