A key step in parameterising speech is to move from the time domain to a domain in which distances make more sense, and so where we can perform pattern matching.
Feature vectors
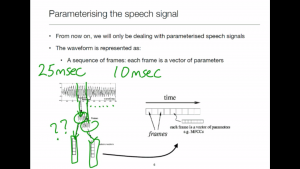
We will make a first attempt at parameterising each frame, but we’ll need to revisit this after learning more about the probabilistic model that will be used.
 This is the new version. Still under construction.
This is the new version. Still under construction.