Just a toy demo, but should give you some idea of how unit selection waveform generation works. Click with your mouse to choose a candidate diphone from each column, then the corresponding synthesised waveform will appear. You can click on the synthesised waveform to hear it again. Try to obtain the most natural-sounding synthesis by trying many different permutations of candidates from those available.
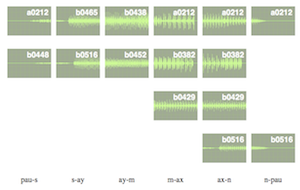 The demo might take a few moments to load all the necessary audio files and images. When it’s loaded it looks like this:
The demo might take a few moments to load all the necessary audio files and images. When it’s loaded it looks like this:
Each diphone is labelled with the ARCTIC utterance that it comes from – click on those labels to play the individual diphones. You’ll find that choosing sequences of candidate units from the same source utterance (that were contiguous in that original utterance) tends to give good results. This is how unit selection using diphone units effectively uses much larger units.
Note that the images of the candidate diphone waveforms have all been resized to the same width, but the actual waveforms will of course vary in their durations.
For simplicity, the synthetic waveform is constructed using naive concatenation of the diphone candidates – it’s not pitch synchronous and there is no overlap-and-add, although the concatenations are made at zero crossings in the waveform.
 This is the new version. Still under construction.
This is the new version. Still under construction.