Forum Replies Created
-
AuthorPosts
-
In Festival, and many other systems, duration is predicted at the segmental (i.e., phone) level. Festival uses a regression tree, because duration is a continuous value.
The tree could directly predict duration in ms or s. But it’s often better to predict what is called a z-score (the figure in that article is helpful). This is the duration expressed as the difference (in numbers of standard deviations) from the mean duration for that phoneme. Here’s what z-score means for duration:
large positive numbers: duration is a lot longer than average
small positive numbers: duration is bit longer than average
zero: duration is exactly equal to the average
negative numbers: duration is bit shorter than average
large negative numbers: duration is lot shorter than averageand we would expect z-scores in a relatively narrow range about the mean (+/- 2 would cover 96% of all cases).
POS is needed in the lexicon to disambiguate homographs. Because POS is the only way to choose the correct pronunciation for words such as “present”, we need to run a POS tagger before trying to look the word up in the lexicon.
In Festival, the lex.lookup_all function will retrieve all matching words and show you their POS tags, for example (for a voice based on the CMU lexicon):
festival> (voice_cmu_us_slt_arctic_hts) cmu_us_slt_arctic_hts festival> (lex.lookup_all 'present) (("present" n (((p r eh z) 1) ((ax n t) 0))) ("present" v (((p r iy z) 0) ((eh n t) 1))))Later in the processing pipeline, the POS tags will also be used to predict phrase breaks.
You have correctly found that this voice does indeed have many missing diphones. A larger or more carefully-designed recording script would not have this problem.
The reason this happens so frequently for this voice is that the diphone coverage was determined using one dictionary (CMUlex) but the voice has been built with a different dictionary (Unisyn). Normally, we wouldn’t do that, but it’s useful for the purposes of this assignment to show what happens when diphones are missing.
The database comprises sentences of connected speech, so does have both within- and across-word diphones.
The database is the awb speaker (i.e., Alan Black himself) from the ARCTIC set of corpora
Footnote: the voice is called voice_cstr_edi_awb_arctic_multisyn which means “built in CSTR / Edinburgh accent / speaker ‘awb’ / ARCTIC corpus / multisyn unit selection engine”
See this topic.
First: how do we come up with the list of possible questions in the first place?
We use our own knowledge of the problem to design the questions, and indeed to select which predictors to ask questions about. It’s not important to choose only good questions because the CART training procedure will automatically find the best ones and ignore less useful ones. So, we try to think of every possible question that we might ask.
Second: during training, how does the algorithm choose the best question to split the data at the current node?
It tries every possible question, and for each one it makes a note of the reduction in entropy (information gain). It chooses the question that gives the best information gain and puts that in to the tree.
Third: what happens if the training algorithm puts a “not so effective” question into the tree?
This will never happen. If the best available question does not give a large enough information gain, then we terminate and do not split that node any further (although the tree can keep growing the other branches).
There is no backtracking: that would massively increase the computational complexity of the training. So, we call this a “greedy” algorithm.
The pronunciation dictionary (written by hand) does not specify an alignment between letters and phonemes. See this topic for an extract from cmulex, showing what is contained in the dictionary.
We need to use this algorithm to find the alignment, before going on to train a classification tree.
Dictionaries are specific to the voice that you are using. The phoneset used is determined by the dictionary. You can use the lex.lookup_all function to query the dictionary one word at a time (without out-of-vocabulary words being passed to the letter-to-sound model).
The dictionary used in the voice_cstr_edi_awb_arctic_multisyn voice is the Edinburgh accent from Unisyn.
To see the phoneset, refer to the symbol tables in Appendix III of the manual (attached), in the “Edinburgh” column.
Attachments:
You must be logged in to view attached files.Phonemes are abstract linguistic types. They describe how a word breaks down into sound units. This is what the academic subject of Phonology deals with. For example, we find that only certain sequences of phonemes are possible in a given language, and some are “illegal”. We might even try to write a set of phonological rules for a language, which would tell us things like /str/ is legal at the start of English words, but /srt/ is not. These are phonological concepts.
A good way to think about phonemes is in terms of “minimal pairs”. If you can find two distinct words that differ in just one sound, then those two contrastive sounds are phonemes. For example “pat” and “bat” tells us that /p/ and /b/ must be different phonemes, and not just different-sounding variants of the same underlying phoneme.
Phones are concrete, individual sound tokens. They are the physical realisation of an underlying phoneme. This is what the academic subject of Phonetics deals with. Phones may vary in their physical properties depending on context.
We write phonemes within slashes /…/ and phones in square brackets […]
As speech technologists, we a guilty of blurring the boundaries between phonology and phonetics. We just want good engineering solutions to problems such as finding a suitable set of sub-word units that we can statistically model to perform speech recognition.
A1: This webpage from John Coleman gives examples of how phones might vary acoustically, whilst being the same underlying phoneme, and confirms that your idea about aspiration being a phonetic process (in English) is correct.
A2: “phonological representation” means the phonemes, possibly with some structural information, such as how they group in to syllables
This model is called a generative model. It generates a word sequence, given a tag sequence. In POS tagging we use it to infer the most likely tag sequence that generated to observed word sequence.
[latex]P(t_i | t_{i-1})[/latex] is the transition probability of tag [latex]t_i[/latex] following [latex]t_{i-1}[/latex]. It’s a language model that injects prior knowledge about what tag sequences are likely.
[latex]P(W_i | t_{i})[/latex] is the emission probability and models how likely that word is, given the tag.
The speech recognition part of the course will help you understand the concept of generative models.
The function lex.lookup calls the complete LTS module that tries the lexicon and then calls the letter-to-sound model if the word is not found.
Use the lex.lookup_all function to only look in the dictionary. This will return ‘nil’ when the word is not found, rather than passing the word on to the letter-to-sound model.
A1: Think of the vocal tract as a set of bandpass filters (one for each resonant frequency), rather than a low-pass filter. The radiation effect at the lips is essentially a constant and has the same effect on all speech sounds.
A2: It should not matter how far from the speakers’ mouth you place the microphone: in theory the signal should be the same (just with reducing intensity further from the mouth). In practice, microphone placement will have an effect if the microphone is directional (e.g., the proximity effect which is evident in the voiceovers of the videos on this site). A perfect omnidirectional microphone recording speech in a perfect anechoic chamber could in theory be placed at any distance from the mouth.
Here are some examples of data that must be hand-labelled before we can apply machine learning (e.g., training a classification tree):
1. letter-to-sound
The hand-labelled data consists of words and their pronunciations, such as this (extracted from cmulex):
... editing eh1 d ax t ih0 ng edition ax d ih1 sh ax n editions ih0 d ih1 sh ax n z editor eh1 d ax t er0 editorial eh1 d ax t ao1 r iy0 ax l ...which is in fact just the pronunciation dictionary that we will already have created by hand. The lexicon may also provide a syllabification of the phoneme string. It does not specify the alignment between letters and phonemes.
2. phrase-break prediction
We will hand-label the phrase breaks in a set of 100s or 1000s of recorded utterances. Where possible, we will use existing data that some kind person has already labelled, such as the Boston University Radio News corpus.
When you say “how many question per word does this process generally need” I think you are referring to how we choose the predictors for training a CART. This is done through expert knowledge, remembering that it’s OK to have a large set of predictors because the CART training procedure will only select the useful ones.
A1: various stopping criteria can be used, such as
– the amount of data is too small (below some manually-chosen threshold) for us to reliably choose a good question to make a split
– all possible splits would result in one of the branches have too few data points (below some manually-chosen threshold)
– none of the possible splits results in a sufficiently large reduction in entropy (again, we set a threshold by hand)
– all data points have the same value for the predictee (i.e., we have perfectly predicted its value for all data points)
A2: regression refers to the case where the predictee is a continuous numerical value; classification refers to the case in the video, where the predictee is discrete
There is nothing special about cross-word diphones compared to within-word diphones. Speech does not have “gaps” between words unless there is a phrase break. We can use diphones recorded within a word to synthesise across a word boundary.
You correctly state that phrase breaks will only occur in places that the front-end predicts. All other word boundaries are just continuous diphone sequences, no different to within the words.
Of course, the number of possible diphones across word boundaries is higher than within words (where phonology constrains the possible combinations). So, we are much more likely to encounter low-frequency (i.e., rare) diphones across word boundaries.
CARTs are used in several places within Festival. The best example is the letter-to-sound model. Look at the file lib/dicts/cmu/cmu_lts_rules.scm in http://www.cstr.ed.ac.uk/downloads/festival/2.4/festlex_CMU.tar.gz which is a letter-to-sound classification tree trained on the CMU lexicon.
Here’s the start of the tree for the letter “a” from that file:
(set! cmu_lts_rules '( (a ((n.name is r) ((p.name is e) ((n.n.name is t) ((p.p.name is h) (((aa0 0.030303) (aa1 0.969697) aa1)) ....etcn.name refers to the predictor “name of the next letter” and the line
(((aa0 0.030303) (aa1 0.969697) aa1))is a leaf, showing the distribution of values for the predictee.
The letter-to-sound CART is trained on the pronunciation dictionary (which was written by hand). Others are trained on hand-labelled data of other types (e.g., speech with hand-annotated phrase breaks).
CARTs can also be written by hand. One reason for doing this is when no training data are available. Here’s an example of a CART for predicting phrase breaks from punctuation.
-
AuthorPosts
 This is the new version. Still under construction.
This is the new version. Still under construction.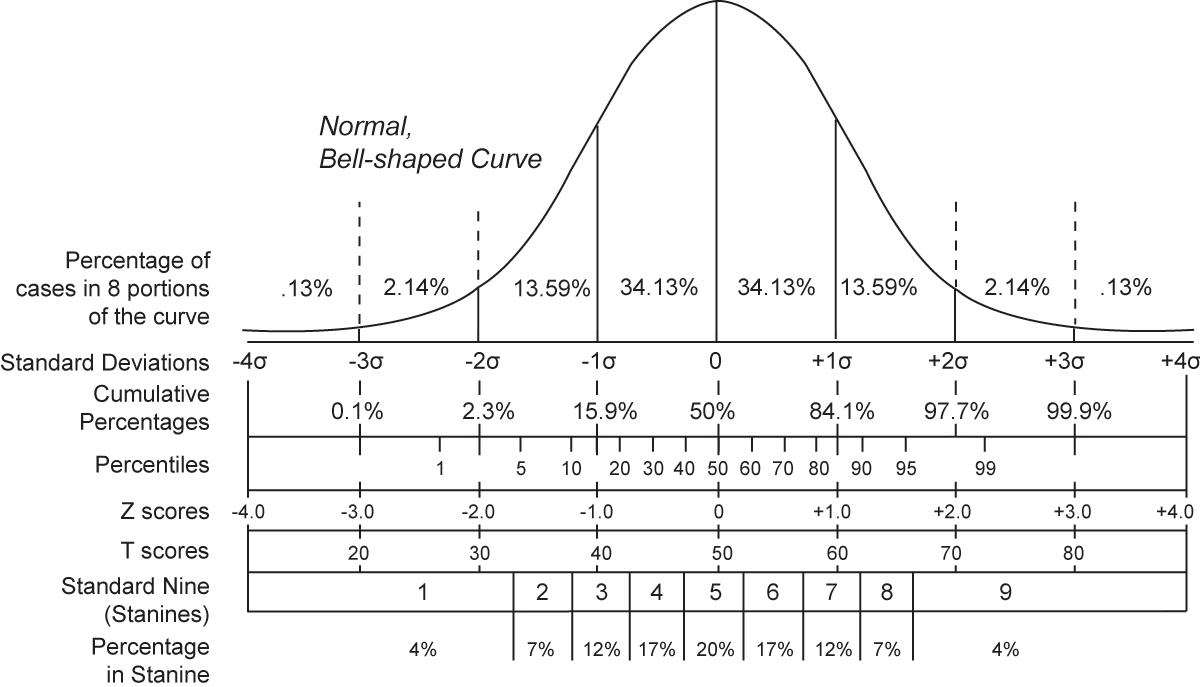{kind=link}