Forum Replies Created
-
AuthorPosts
-
We’ll look at this in the lecture.
We’ll look at this in the lecture.
By “arbitrary point” Taylor means that the acoustic features take continuous values (e.g., F0 in Hz) rather than discrete values (e.g., “stressed?”)
Those acoustic values have been predicted, given the linguistic features. We actually already know how to build a model to make such predictions – see Speech Processing…
I think you’ve just missed one simple point: it will not be possible, in general, to find any candidates in the database that have exactly the same linguistic specification as the target.
In your example, where you are using phone-sized units an an ASF target cost, your target specification is “phoneme /n/ with an F0 of 121Hz and a duration of 60ms”. It is very unlikely that we will find a candidate with exactly those values. Imagine that we find these candidates:
- phoneme /n/ with an F0 of 101Hz and a duration of 63ms
- phoneme /n/ with an F0 of 120Hz and a duration of 93ms
- phoneme /n/ with an F0 of 114Hz and a duration of 56ms
None of these will have zero target cost.
1) A simple way to do that would be to add the fillers (e.g., “Hmm”) as words in the dictionary. You can then make sure there are some example recordings of that word in your database. Try it and see if it works…
2) We’ll discuss intelligibility etc in the lecture on evaluation, so please ask this question again at that point.
Yes – spot on.
The decision tree is in fact performing a regression or classification task. Given the linguistic features, it is predicting which units in the database would be suitable to use for synthesising the current target position.
If we think of the tree as providing one or more candidate units at each leaf, it is performing classification.
We can also think of it as a regression tree that is predicting an acoustic specification, represented either as a set of exemplar units or (as you say) a probability density. The latter is how HMM-based speech synthesis works.
December 11, 2015 at 15:03 in reply to: How to view and author posts that include code or maths #1102Maths looks fine on Chrome for iOS
Yes, that’s correct. Gain is simply a technical term for the amount by which a signal is multiplied.
Vocal tract length
On average, men have slightly longer vocal tracts than women, and so the formants in male speech will be a little lower than in female speech.
Fundamental frequency
Generally, male speech has a lower fundamental frequency (F0). This is due to a combination of anatomical differences, both in the vocal folds themselves and the larynx. This article seems to summarise the factors quite well.
For this course, you do not need to be able to state or derive formally what the computational complexity of algorithms is, although you should understand informally that some algorithms are more complex (i.e., require a larger number of computations) than others.
Nevertheless, it’s still useful to understand computational complexity. Let’s just keep things informal here and only mention the most important case, and that is the complexity of a CART when we are using it at ‘run time’:
Computational complexity of using a CART to classify an unseen data point
This depends on the depth of the tree, because that determines how many questions you need to ask about the predictors. The depth of the tree is proportional to the logarithm (to base 2) of the number of leaves. This is very nice: the logarithm of a number grows slowly as that number gets larger. So, even trees with very large numbers of leaves will not be very deep. For example, a tree with 1000 leaves will only have a depth of around 10. That makes CARTs very fast to use: asking 10 binary questions about predictors will be computationally very fast.
What is the depth of a tree?
This is the number of edges (the edges join up the nodes) from the root to a leaf. The depth might vary in different parts of the tree, of course.
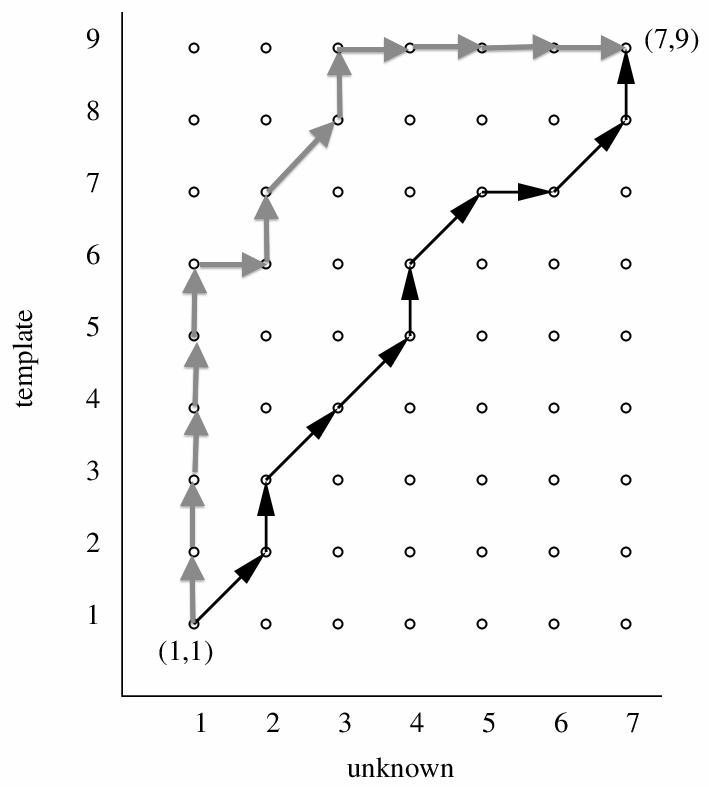
Think about the grid, which is the data structure used for Dynamic Time Warping. Paths from one corner to the diagonally-opposite corner must pass through the points on the grid, summing up local distances as they go. Paths close to the main diagonal generally pass through fewer points in total than paths that stray far away from the main diagonal.

You can see in the diagram above how the two paths differ in the number of local distances that they must sum up. This leads to a bias in favour of paths that stay close the the main diagonal.
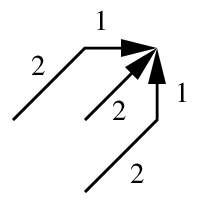
To reduce this bias, lots of solutions were proposed back at the time when DTW was the state-of-the-art. One is to penalise diagonal paths (e.g., add a penalty cost to the distance-so-far every time a diagonal move is made). One popular method was to impose local constraints, such as in this diagram (the numbers are weights or penalty terms):
Is this still important?
For automatic speech recognition, this is all outdated and no longer important. But there is a general lesson that might apply to other applications of dynamic programming: look for biases towards certain solutions, and ask whether that needs to be compensated for.
You’re mixing up two distinct processes.
Warping the frequency scale
There are a variety of perceptually-motivated frequency scales, and we could choose any of them (Mel, Bark, ERB, …). They all have something in common, and that is that they are non-linear. This non-linearity might or might not be implemented as a logarithm, but note that we are not taking the logarithm of the energy of the speech signal, we are just warping the frequency scale. Think of it as stretching the vertical axis in a spectrogram so that the lower frequencies occupy more of the scale, and that higher frequencies are squashed into less of the scale.
Taking logarithms of filterbank outputs
Here is where taking logs is crucial: this is the point at which we convert a multiplication in the frequency domain (the source spectrum has been multiplied by the vocal tract frequency response) into an addition (a sum) in the cepstral domain.
After that multiplication-to-addition conversion, then we can split the source and frequency contributions to the sum. This is possible because their contributions are at different quefrencies. By using a cosine series expansion, we spread these contributions out along the quefrency scale and can then – for example – ignore those parts that relate to the source.
HInit performs uniform segmentation, immediately followed by Viterbi training. The output that you are seeing for several iterations is for the Viterbi stage of training.
Next, let’s write a script that calls another script, and passes a value to it on the command line. Here are the two scripts:
#!/bin/bash MYVARIABLE=$1 echo "This is the child script and the value passed was" ${MYVARIABLE}and
#!/bin/bash # this is the parent script echo "This is the parent script and it is about to run the child script three times" ./scripts/child.sh one ./scripts/child.sh two ./scripts/child.sh three echo "Now we are back in the parent script" echo "Let's get smarter and write code that is easier to maintain" for COUNT in one two three do ./scripts/child.sh $COUNT done echo "Pretty nice - but we can do even better and read in the list from a file" for FRUIT in `cat lists/fruit_list.txt` do ./scripts/child.sh ${FRUIT} done echo "Much better. Now let's save the output to a file so we can inspect it later" echo "This method will overwrite the contents of the file, if it already exists" (for FRUIT in `cat lists/fruit_list.txt` do ./scripts/child.sh ${FRUIT} done) > output.txt echo "Another way is to append lines to an existing file" echo "This line will appear in the file" >> output.txt for FRUIT in `cat lists/fruit_list.txt` do ./scripts/child.sh ${FRUIT} >> output.txt done echo "Now you need to look at the file just created, called output.txt" echo "For example, you could now type 'cat output.txt' or open it in Aquamacs"and the file fruit_list.txt contains
apples bananas pears oranges
now let’s run it
$ ./scripts/parent.sh
I’ve attached a zip file containing everything you need.
Attachments:
You must be logged in to view attached files.Once per utterance to be recognised.
I think this topic could help – read it through, then post any follow up questions there.
The key idea is that the language model and the acoustic models (HMMs) have been compiled together and therefore are just one big HMM. Token passing is performed on that.
Put this line
set -x
somewhere near the start of your script. It will cause the complete HVite command line to be printed just before it is executed. That will help you see what is wrong with the arguments you are passing to HVite.
The shell is trying to execute “resources/word_list_seq” which obviously should never happen – you might have a space after one of the “\”, or blank lines or comments in the middle of the HVite command, perhaps.
-
AuthorPosts
 This is the new version. Still under construction.
This is the new version. Still under construction.