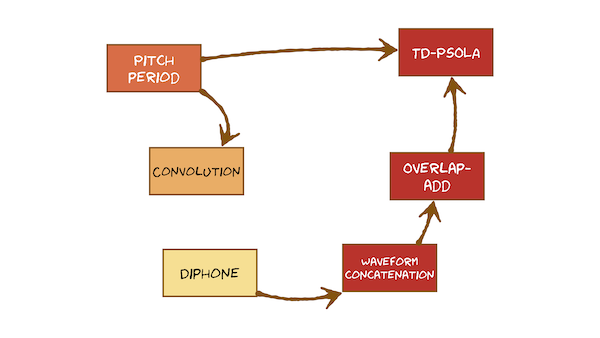
It’s time to bring together everything we learned earlier about speech signals and the source-filter model, and use that to develop a method for creating synthetic speech. This course only covers one method, which uses a database of recorded natural speech from which small waveform fragments are selected and then concatenated. These waveform fragments are of special sub-word units called diphones. Because they are taken from natural recordings, they will have an F0 and duration but these might not match the values we predicted in the front end. Therefore a method is needed to modify these properties, without changing the spectral envelope.
Here’s what you’re going to learn in the videos:
We’ve also included a second tab of videos on connected speech. We won’t go into this topic too much right now, but wanted to shared them with you in case they are helpful for thinking about potential errors in TTS (for assignment 1).
Lecture Slides
Slides for Thursday lecture (google) [updated 25/10/2023]