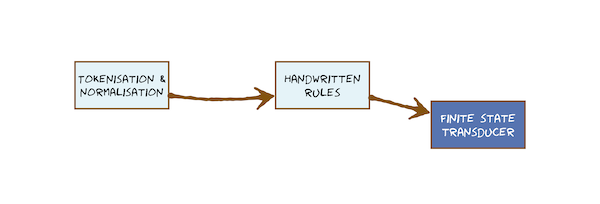
In this module, we will introduce the concept of concatenative speech synthesis and learn about the first stages of text processing for Text-To-Speech (TTS). This is usually call the front-end of a TTS system. This involves converting text to a form in which we can characterise the acoustic features we want to generate in spoken form.
A crucial part of this is how to predict the pronunciation of words from their spelling: the task called grapheme-to-phoneme (G2P) or letter-to-sound (LTS). For some languages, G2P can be performed by rules, but for English we need a large dictionary, plus machine learning to extrapolate from that dictionary to unseen words. To specify the pronunciation of words, we need a language-specific inventory of phonemes. Our first look at phonemes is from an engineering point of view, considering their practical use in TTS.
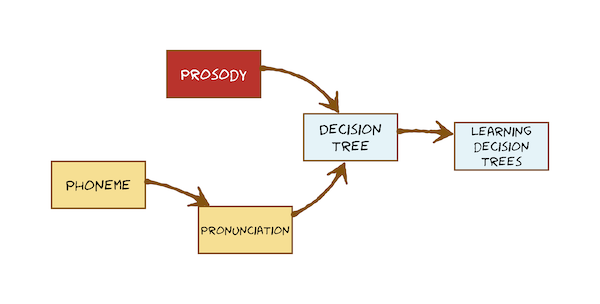
The second problem that is too hard to solve with hand-crafted techniques is the prediction of prosody. We define what prosody means, again from an engineering perspective.
To solve both problems requires machine learning, and so comes our first encounter with that. We use Decision Trees for G2P and for prosody prediction. Here’s what you’re going to learn in the second sequence of videos:
We will also take a more thorough look at the concept of the phoneme, from a linguistic perspective. We will look at the important concept of the allophone and how this can affect which phones we actual want to generate from text. Listeners have a remarkable ability to cope with high acoustic variability within categories, an important aspect of spoken language that will come back later in the course when we look at Automatic Speech Recognition.
Lecture Slides
Slides for Thursday lecture (google slides) [updated 15/10/2024]