
In this module, we will introduce the concept of concatenative speech synthesis and learn about the first stages of text processing for Text-To-Speech (TTS). This is usually call the front-end of a TTS system. This involves converting text to a form in which we can characterise the acoustic features we want to generate in spoken […]
January 2, 2016
Interactive unit selection

Just a toy demo, but should give you some idea of how unit selection waveform generation works. Click with your mouse to choose a candidate diphone from each column, then the corresponding synthesised waveform will appear. You can click on the synthesised waveform to hear it again. Try to obtain the most natural-sounding synthesis by […]
October 18, 2014
TD-PSOLA …the hard way
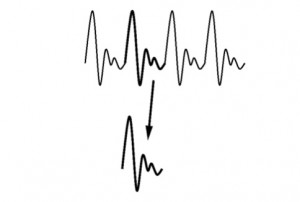
Time-Domain Pitch Synchronous Overlap and Add (TD-PSOLA) can modify the fundamental frequency and duration of speech signals, without affecting the segment identity – that is, without changing the formants. Normally, it’s an automatic algorithm, but here we do it the hard way – by hand! If you want to follow-along, you will need Audacity and these materials (a […]
October 11, 2014
A simple synthetic vowel
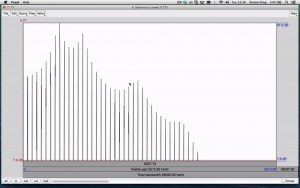
Using Praat, we synthesise a simple vowel-like sound, starting with a pulse train, which we pass through a filter with resonant peaks.
October 11, 2014
Pipeline architecture for TTS
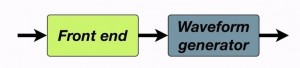
Most text-to-speech systems split the problem into two main stages. The first stage is called the front end and contains many separate processes which gradually build up a linguistic specification from the input text. The second stage typically uses language-independent techniques (although they still require a language-specific speech corpus) to generate a waveform. Here we see those two […]
February 6, 2012
My inaugural lecture

I talk about how speech synthesis works, in what I hope is a non-technical and accessible way, and finish off with an application of speech synthesis that gives personalised voices to people who are losing the ability to speak. I also try to mention bicycles as many times as possible. For a more up-to-date, slightly more technical, […]
 This is the new version. Still under construction.
This is the new version. Still under construction.