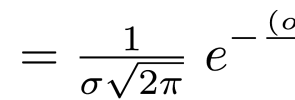I talk about how speech synthesis works, in what I hope is a non-technical and accessible way, and finish off with an application of speech synthesis that gives personalised voices to people who are losing the ability to speak. I also try to mention bicycles as many times as possible.
For a more up-to-date, slightly more technical, and entirely bicycle-free talk on the same topic, try my ULAB 2018 keynote.